MIT Song Han 교수님의 EfficientML 강의를 듣고 배운 내용을 정리하기 위한 포스팅이다.
Instructor: Prof. Song Han
Slides: https://efficientml.ai
Course - MIT HAN Lab
Course collection of MIT HAN Lab.
hanlab.mit.edu
Primitive operations
how human designs NN?
group conv, depthwise conv
Reduce parameters and MACs
Classic building blocks
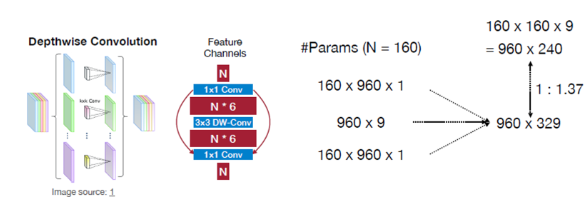
MobileNet은 계산량을 줄이기 위해 Depthwise Separable Convolution을 사용
- Depthwise Convolution은 각 채널별로 독립적인 필터를 적용하고, Pointwise Convolution으로 채널을 결합.
- MobileNet : depthwise conv, 1x1 conv
- Resnet은 bottleneck이 발생한 부분에 channel을 축소하여 연산량을 감소시켰음. 하지만 mobilenet은 극단적으로 채널수가 감소했기때문에 반대로 늘려줌 → inverted bottleneck
- MACs를 비교해보면 원래대로 연산한 양과 depthwise conv로 연산했을때 비슷한 것을 알 수 있다(1:1.3)
- 3개의 conv를 사용하는 것과 1개의 conv를 사용하는 것을 비교하게 되면 3개의 activation도 저장해야하고 더 많은 연산량이 필요함
- 하지만 GPU의 발전으로 그 범용적인 인기는 줄어들었음.
Model 사이즈가 많이 작아 졌는데 어떻게 peak activation은 증가한 것일까?

Bottle Neck과 inverted Bottle Neck을 비교하게 되면 On chip SRAM에 저장하기위해 많은 buffer가 필요함.
즉, 파라미터 관점에서 관찰하면 depthwise conv가 매우 유용하지만 inference나 training을 할때 activation의 관점에서는 영향이 미미하다.
- Group Convolution은 채널을 여러 그룹으로 나누어 각 그룹에서 독립적으로 Convolution을 수행
- ResNeXt : group conv
- ShuffleNet은 group conv를 수행하는 group끼리만 연관되고 나머지는 independent함.
- Group끼리 shuffle을 진행해서 모든 group들이 섞이게 함.

Neural Architecture Search

기존에는 사람이 manually 여러 hyper-parameter를 지정했었다.

위 그림을 보면 원 내부가 별표인 것들은 machine이 design한 모델인데 이것을 관측해봐도 low MACs로 high Accuracy를 잘 찾아 낸 것을 확인할 수 있음.
이제 NN로 search하도록 한 것인데, → design the model , search space, search strategy

Cell- level Search Space

네트워크 구조를 탐색하는 과정에서 가능한 모든 조합과정을 고려하는 것이다.
위 예시는 RNN 모델을 선택하는 과정을 담고 있으며, 두 개의 입력과 M개의 후보 연산, N개의 hidden state를 결합하는 방법, B개의 layer가 있는 경우에 search space의 크기는 얼마인가?에 대해 다루고 있다.
- 2: 두 개의 입력을 선택할 수 있는 방법
- M: 각 hidden state에서 선택할 수 있는 연산(e.g. conv, maxpool, fc)
- N: hidden state를 결합하는 방법의 수(e.g. cat, add)
- B: 전체 layer의 수
Network- level Search Space
cell-level search space가 있다면 network level로도 존재함.
depth, resolution, width, kernel-size, topology connection 등을 선택하는 방법이 있다.
kernel size의 선택에서

위와 같이 5x5 kernel과 3x3 kernel 2개의 선택권이 주어졌을 때, 두 방법의 장단점은 무엇일까? 많이들 알고 있겠지만 두개의 receptive field는 동일하지만 parameter의 개수 측면에서 3x3이 효율적이라는 것을 알 수 있다.
그렇다면 activation의 관점에서는 어떨까? 5x5는 1개의 layer만을 갖고 있기에 1개의 activation을 갖게 된다. 이것은 activation을 저장하기 위해 적은 GPU 메모리를 요구하게 된다.
??질문?? GPU 메모리를 적게 요구하는 이유가,,? HBM에서 GPU cache사이의 이동을 절약할 수 있다는 관점인건가///?
그래서 5X5가 낫다.,,3X3이 낫다 아니면 7X7이 낫다라는 판단은 어렵다고 생각이 되고, 결국은 병렬화와 메모리 저장 연산 등 다양한 것들을 고려하여 network를 search해야한다.

위 search space는 topology connection을 의미하고, 왼쪽 그림을 보면 L개의 layer마다 다양한 choice들이 존재한다. 계속해서 downsample을 할 수도 있고, 다시 upsampling을 할 수도 있고, resolution을 유지할 수도 있다.다만 input과 output의 resolution만이 task가 사전에 선정한대로 일어난다면 그 중간 과정에서는 어떠한 resolution의 변화도 모두 허용이 된다.
지금까지 고려한 모든 경우는 너무 커서 이를 다 관측하기에는 한계가 있다. 그래서 우리는 narrow down search space를 하여 optimize search space를 하고 최종적으로 model specialization을 하게 되는 것이다.
만약 우리가 edge device에 model을 배포한다고 하자. 그러면 많은 constraint가 존재한다. latency, energy, memory constraint 가 그 예이다. 현재 mobile device에 적합한 모델은 많이 개발되어잇지만 IoT에 배포되기위한 개발은 여전히 미미하다. 이를 Tiny AI라고 하고 KB수준의 적은 메모리 할당이 가능하다.

우리는 design space를 TinyML을 위해 디자인하는 것이 목표이다.
일단, Data Movement가 비싼 것이지 Computing은 매우 싸다는 것을 알자. 만약 동일한 양의 data movement가 발생하고, 어떤 모델이 매우 큰 FLOPs를 갖는다고 하자. 이것은 capacity가 크다는 것을 의미한다.
즉, Larger FLOPs -> Larger model capacity -> More likely to give higher accuracy
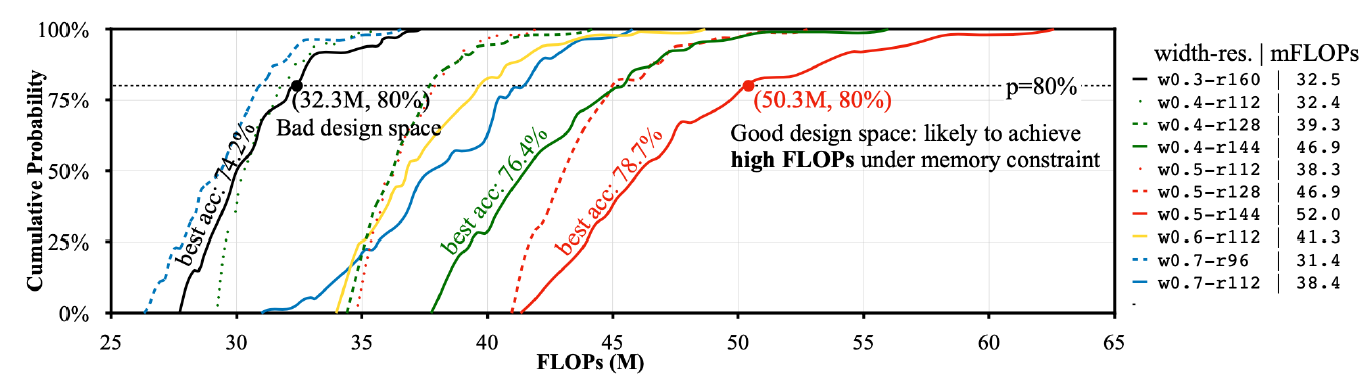
위 그래프에서 봤듯이 동일한 양의 footprint를 가지면 FLOPs가 더 많이 수용가능할수록 좋은 design space라는 것을 알 수 있고, 많은 연산을 수행할 수 있다는 것을 암시한다.

위 결과를 보면 random한 search space보다 우리가 선정한 search space가 더 정확한 성능을 보였고, baseline model과 비교해보았을 때 baseline model은 OOM(Out Of Memory)이지만 우리가 search한 모델은 비교적 비슷한 성능으로 100KB SRAM의 메모리 제약을 충족하는 모델을 찾을 수 있었음을 보여준다. 메모리 이동이 비싸기 때문에 연산이 많이들더라도 메모리가 적게 사용되는 Space를 선택하는 것이 중요하다.
Search Strategy

Search Space를 정의했담녀 이제 Strategy를 정립 해야한다.
Grid Search
2개의 변수를 선정해서 scale을 정하고 그 grid에 있는 모델들을 실험적으로 확인한다. (e.g. resolution in [1.0x, 1.1x,1.2x], width in [1.0x, 1.1x, 1.2x])
또는 Efficient Net을 보면 Depth, Width, Resolution을 변수로 다양한 변수들을 종합하여 scaling하는 기법을 적용하였다.

위 그림을 보면 baseline보다 더 깊어지고 해상도가 높아지고 channel수가 증가하여 2배의 FLOPs를 가지는 최적화된 모델을 찾을 수 있는 것이다.
Random Search
성능이 꽤 괜찮고, widely 사용된다. 그 이유는 계속적으로 random하게 search를 하면 점진적으로 loss가 감소하는 것을 알 수 있다. 이를 통해 모델의 건전성(?)을 평가할 수 있는 것이다.
Reinforcement Learning
강화학습을 통해 RNN Controller가 제안한 모델을 sample해보면서 controller를 best architecture를 선택할 수 있는 방향으로 update한다.

Gradient Descent

모든 가능한 선택지들을 연속적인 공간에서 표현하여, 아키텍처를 미분 가능한 방식으로 최적화하는 기법이다.
DARTS는 모든 가능한 연산에 대해 가중치를 학습하고, 중요도가 높은 연산이 더 크게 반영되도록 점차 선택하게 되는 것이다.
결국 이번 6강에서는 효율적인 모델을 search하는 방법론에 대한 소개를 한 것이다.
처음에 원시적인 방법인 group convolution이나 depth-wise convolution을 소개하면서 모델의 연산과 메모리 효율을 높일 수 있는 방법에 대해 소개했다.
그리고 이 뿐만 아니라 다른 요소들을 cell level (예컨대 어떤 연산을 할지 어떤 input을 선택할지) 또는 neural level (예컨대 layer의 깊이, kernel의 사이즈, hidden dimension등)을 search하는 다양한 방법들을 소개했다.
'EfficientML' 카테고리의 다른 글
| EfficientML.ai Lecture 16 - Diffusion Model (MIT 6.5940, Fall 2023) (0) | 2024.10.25 |
|---|---|
| EfficientML.ai Lecture 13 - Transformer and LLM (Part II) (MIT 6.5940, Fall 2023) (1) | 2024.10.22 |
| EfficientML.ai Lecture 12 - Transformer and LLM (MIT 6.5940, Fall 2024) (1) | 2024.10.21 |
| EfficientML.ai Lecture 6 - Quantization(Part 2) (6) | 2024.09.05 |
| EfficientML.ai Lecture 5 - Quantization(Part 1) (3) | 2024.09.05 |