https://www.youtube.com/watch?v=nFE1euQ_Wtw
Basics of diffusion model
• Denoising diffusion models

DDPM은 2가지 process로 구성되어있다. noise를 점진적으로 추가하는 forward process를 정의하고 이 것의 반대과정을 도출한 것인 reverse process를 학습하여 data를 generate하는 것이다.
GAN과 비교해보았을 때, DDPM은 iterative mapping을 Gaussian noise로부터 정의하여 생성과정 역시 step by step이지만, GAN은 한번의 step만으로 데이터를 생성한다.

original data x0에서 노이즈를 점진적으로 주입하면 시간의 흐름에 따라 Xt가 되고 T까지 noise를 주입한 XT는 N(0,I)를 따르는 Gaussian분포가 된다. noise를 주입하는 variational scheduler beta를 정의하고 이 값을 이용하여 평균과 분산을 정의한다. 그렇게 되면 t시점의 x는 이전시점의 x의 평균과 분산에 영향을 받는 x가 되고, x0까지 연속적으로 적용하면 x0와 관련된 식으로 나타낼 수 있다.

위 식에서 도출한 결과를 통해 q(xt|x0)의 분포식을 나타낼 수 있고, X0로부터 xt를 바로 샘플링할 수 있게 된다.
이 때, 특이한 경우로 at=0이라면 표준정규분포를 따르게 되어 , xT가 N(0,I)를 따르는 분포가 된다.
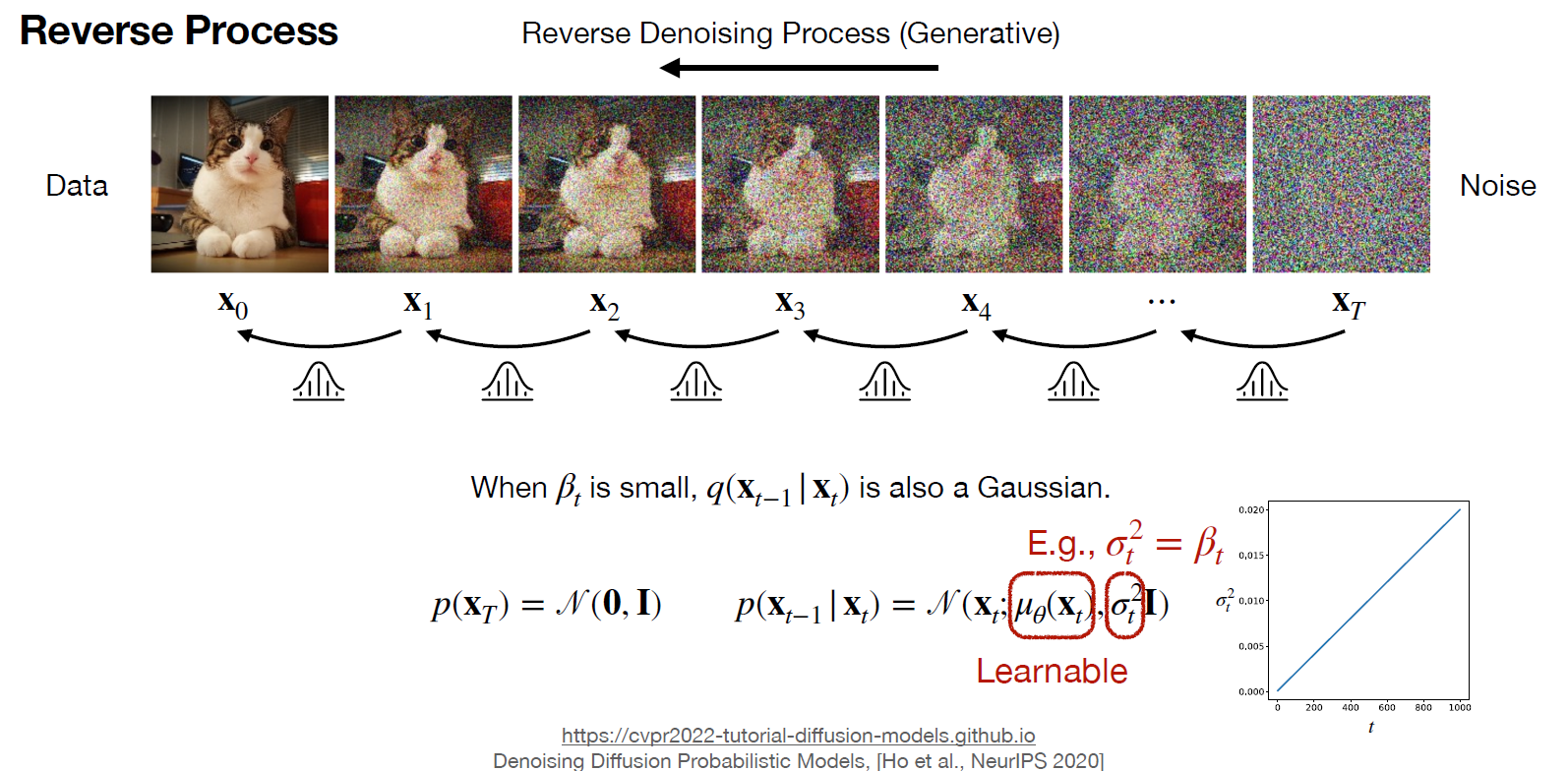
위에서까지 정의한 forward 분포를 bayesian rule을 통해 reverse process도 gaussian이라는 것을 알아냈고, 평균과 분산을 파라미터로 하는 p의 분포를 NN으로 추적하면 되는 것이다.

이를 최적화하는 과정에는 위에서 정의한 Objective Function을 최소화하면 되는데, 왼쪽에 쓰여있는 Eq[-logp(x0)]를 최소화하여 real data를 생성하는 그럴듯한 분포를 만들면 된다. 그러기 위해서는 우측의 항이 가장 작아지도록 하면되는데,
해석하면 X0가 주어진 q의 분포가 파라미터로 학습된 분포인 p의 분포와 유사해지도록 하는 것이다.
다음식을 t시점에 따라 3개의 term으로 나누고 첫번째 term은 종착지인 T에서의 X분포가 유사하도록하는 KL을 최소화하면되는데, 이는 상수로 고정된 값을 얻을 수 있다. 두번째 term은 t가 2인 시점부터의 KLD를 구하는 것이고, 이 과정에서는 연산이 필요하다. 그리고 세번째 term은 t=1일때, KLD를 구하는 것이고, 파라미터를 업데이트할 때는 매우 작은 값이라 무시하는 경향이 있다고 한다.

위식에서 두번째와 세번째 TERM을 유도한 방식인데, q의 평균과 p의 평균은 아래와 같이 정리하여,

정리하면 결국 t에 따른 epsilon의 연산으로 정리가 되고, 더해진 노이즈를 예측하는 수식으로 간단히 정리가 된다.


학습하는 알고리즘을 도식화한 식을 보면, 특정 시점까지 더해진 노이지한 입력값에서 U-Net을 거쳐 그 시점까지 주입된 노이즈를 예측하는 것을 나타내고 노이즈를 예측하는 모델로는 U-Net을 사용한다.

sampling을 진행할 때는 t시점에서의 입력값에 alpha를 변형한 값을 곱해서얻는다.
• Conditional diffusion models
particular class나 text, 또는 pixel wise condition을 추가적으로 조건을 준 것이다.

- Scalar Condition
class ID를 추출된 feature map의 channel수에 맞게 representation을 mapping시키고, 서로다른 shape이라도 broadcast add를 통해 연산.

-Text Condition
Cross Attention을 적용해서 img token과 text token간의 연산을 통해 feature map을 생성한다.

-Pixel-wise Condition

downsample branch에 zero convolution을 더해서 처음에는 아무것도 안더하고 안곱한 효과지만, 학습을 진행하여 값이 생기면 condition을 pixelwise 더해주는 효과를 냄.
-Classifier Guidance

위 그림에서 알 수 있듯 추가적인 classifier를 더해주어 condition에 맞게 분류하도록 설정한다. 그리고 w로 class를 guide할 정도를 결정한다.


-Classifier Free Guidance
추가적인 classifier 학습없이 아래 bayesian rule을 정리해서 conditional model과 unconditional model 2개를 forward해서 w로 그 강도를 조절하는 방법으로 guide를 줄 수 있다. 이 방법은 condition이 sclar, text, pixel-wise 어느 것에도 제약이 없고, 추가적인 classifier 학습이 필요없다는 장점이 있다. 하지만 forward를 2번해야해서 2배의 FLOPs가 필요하다는 단점이 있다.

• Latent diffusion models
그냥 DDPM을 적용하기에는 너무 큰 해상도를 요구하여 연산량이 너무 많다. 이를 보완하기 위해 latent space로 embedding하는 stable diffusion을 제안하였고, training 알고리즘과 도식은 아래와 같다.

sampling시에는 T시점의 gaussian noise로부터 사전에 정의된 T step만큼 denoising을 하여 z0를 얻고 이를 decoder를 통과시켜 reconstruction img를 얻는다.

• Image editing
- SDEdit (Stroke-Base Editing)

-Text-Base Editing
attention map에서 변경된 단어와 관련된 부분만 update하면 된다.

• Model personalization
-DreamBooth
본 모델은 주어진 img에 새로운 text를 주입했을 때, 새로운 context를 반영해서 올바르게 재현(fidelity)하였다.

입력으로 class와 관련된 소량의 이미지와 class ID가 주입된다. 이 것이 사전학습된 Text2Image모델을 finetuning하여 그 subject를 인식할 수 있는 personalize된 모델을 얻게 된다. 이 모델은 고유토큰을 이용하여 subject를 인식하고 다양한 스타일이나 상황에 적용할 수 있게 된다. 하지만, 이 방식은 하나의 subject에 대해 한번의 fine-tuning을 거쳐야하기 때문에 computational cost가 비싸다는 단점이 있다.
-FastComposer
기존 연구는 subject가 2개 이상이면 성능이 떨어지고, reference image에 overfitting하는 문제가 있었다. (limited composability, limited editability).
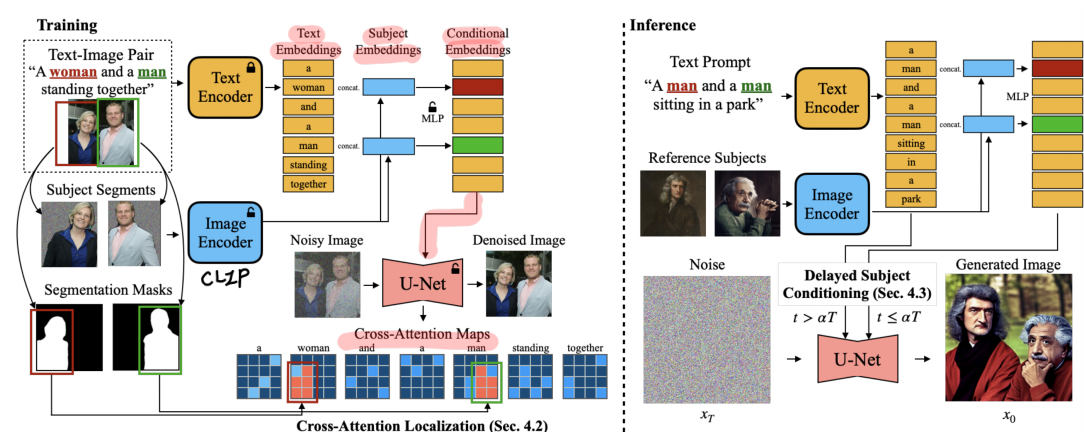
이러한 한계를 보완한 방법으로 . cross attention map을 localization하였다. 이 방법은 text embedding과 img encoder를 거쳐 나온 subject embedding을 concat하여 단어와 관련된 pixel을 찾아 그 부분을 더 세밀하게 일치시킨다.
Fast sampling techniques
• Denoising diffusion implicit models
-DDPM
Markovian을 따라서 현재 output은 직전의 output에 기반하여 분포가 형성되어 순차적으로 생성된다. (only depend on the previous step)
-DDIM
이전 step에서 추측하는 것이 아니라 x0를 추측하여 현재를 출력하는 모델이다. 중간 단계를 생략(즉, step을 skip)하면서도 결과적인 이미지 품질에 큰 손실이 없도록 설계되었습니다. DDIM은 deterministic한 방식(ODE)으로 노이즈 제거 과정을 더 빠르게 진행할 수 있게 합니다.



• Progressive distillation

teacher step에서 2개의 인접한 sampling과정을 student step에서 1개로 합쳐서 distililation을 진행하는 것.
• Guided distillation
앞서 설명한 classifier free guidance에서 condition이 있는 모델과 없는 모델 2개의 forward process가 필요해 FLOPs가 두배 필요했다. 이를 한번만해도 출력이 나오도록 distillation을 진행하여 deterministic sampler를 얻는 방법이다.
Acceleration techniques
• Sparsity
선택된 일부분만 update하고 나머지 영역은 기존에 계산한 feature map을 재사용하는 방법이다.

• Quantization
-Time Aware calibration
다른 time step에서 다른 scaling factor를 사용함.
인접한 시간에서의 출력분포는 비슷하지만 거리가 생기면 다르게 나타나기 때문에 시간에 따라서 weight과 activation의 scaling factor를 조정함.

-Shortcut-Splitting Quantization

모델 구조에서 shortcut이나 skip connection을 다르게 처리하여 quantization 성능을 높이는 방법으로 concat하는 구간에서 downsampling에서 얻어진 weight이나 activation의 quantize와 upsampling과정에서 얻어진 weight이나 activation의 quantize를 다르게 처리하는 방법.