EfficientML.ai Lecture 13 - Transformer and LLM (Part II) (MIT 6.5940, Fall 2023)
1. Efficient inference algorithms for LLMs
(1) Quantization : SmoothQuant, AWQ, TinyChat

qunatization : 실수 r을 정수 q로 양자화하여 실수 scaling factor를 이용하여 압축하고 복원하는 과정을 의미함.
[ 연산을 단순화하면서 성능 저하를 최소화하는 것이 목표]
- SmoothQuant(W8A8)
8bit로 weight와 activation을 양자화 하는 방식으로 CNN에서 널리 사용하지만 LLM에서는 특정 크기 이상에서는 LLM의 activation outlier들이 발생하여 성능이 급격히 하락하는 것을 알 수 있다.
이를 극복하기 위해 Activation에서 발생하는 양자화 문제를 일부 Weight로 이동시킴.
smoothing을 통해 더 이상 outlier가 발생하지 않도록 만들고 actiavtion가 quantize되기 쉬워지게 만들고 weight는 slightly harder가 되더라도 여전히 easy하도록 만든다.
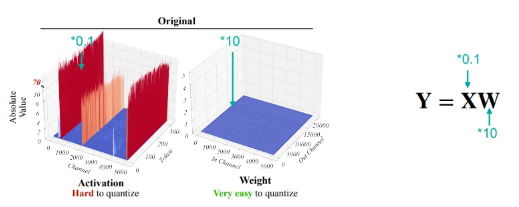



SmoothQuant는 Accurate and efficient quantization of various LLMs
finetuning없이 성능을 유지시킨다. inference를 가속화하고 memory footprint를 줄여주었다.
LLaMA family에서 losslessly qunatize하였고, hardware barrier를 낮추었다.
-> 이 방법은 batch serving에는 좋지만 single-query LLM inference에서는 여전히 highly memory-bounded였다.
-AWQ (Activation-aware Weight Quantization)
memory bandwidth를 낮추기 위해서 도입된 방법으로, 특정 중요 channel만 FP16으로 유지하면 성능저하를 막을 수 있음.

모든 Weight를 낮은 정밀도로 양자화하는 대신, 1% 정도의 중요한 가중치 채널은 여전히 FP16으로 유지할 때 성능 개선 효과를 볼 수 있음.


가중치를 scaling factor(Δ)로 나눈 후 반올림을 하는 방식으로 양자화하여 Q(w)를 얻는다. (Δ는 가중치의 최대 절대값을 기준으로 scaling factor가 결정됨.)
얻어진 Q(w)에서 activation이 중요한 부분만 간단히 s를 곱해 스케일링함으로써 손실을 줄인다.
-TinyChat

AWQ 4bit model로 실행되며, on-device LLM의 가능성을 보여주었다.
(2) Pruning/sparsity : SpAtten, H2O, MoE
[Attention Sparsity]
-Wanda
AWQ와 유사한 아이디어로, activation의 distribution도 함께 고려한 방법이다. |weight|*||activation||을 기준으로 가중치를 pruning을 한다.
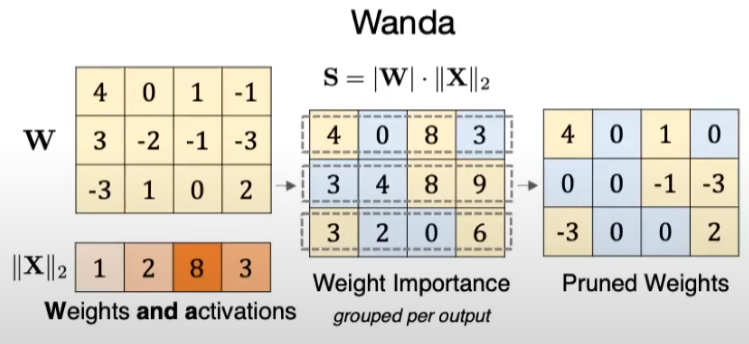
-SpAtten
토큰을 점진적으로 layer마다 조금씩 pruning을 진행하므로 cascade라고 하고 아래 예제를 보면 처음에 11개의 token으로 시작되었지만 layer를 거쳐 2개의 token만을 남기고 classification을 가능케한다.

위 오른쪽 attention map에서의 수직 누적합을 관찰하면 숫자가 높을수록 중요도가 높다는 것을 알 수 있고, 그 값이 낮으면 pruned away하는 것을 알 수 있다.
-H2O(Heavy Hitter Tokens)
중요 토큰(heavy hitter tokens, H₂)을 KV 캐시에 유지하면서, 덜 중요한 토큰은 제거하여 메모리 사용을 최적화하는 방법이다.

AR Model이기 때문에 attention map이 삼각형 모양이고 수직으로 합쳤을 때, 그 값이 특정 역치 이하면 pruning을 진행한다. 오른쪽 그래프를 통해 H20가 모델의 크기를 많이 reduce하더라도 acc의 하락이 크지 않음을 알 수 있다.
[Contextual Sparsity : input에 영향을 받음]
-DejaVu
Predictor를 attention layer와 mlp layer와 병렬적으로 추가하여 어떤 attention layer를 pruning할지 FFN에서 어떤 channel을 pruning할지를 결정함. 이 방법은 latency를 줄일 수 있는 장점이 있다.

- MoE

router에서 입력 데이터를 보고, 다양한 FFN 중에 가장 확률이 높은 FFN을 거치도록 workload를 distribute한다.
Softmax와 같은 확률 기반 방법을 사용하여 각 전문가에 할당되는 확률을 계산하고, 그 중에서 가장 높은 확률을 가진 몇몇 전문가만 선택한다.
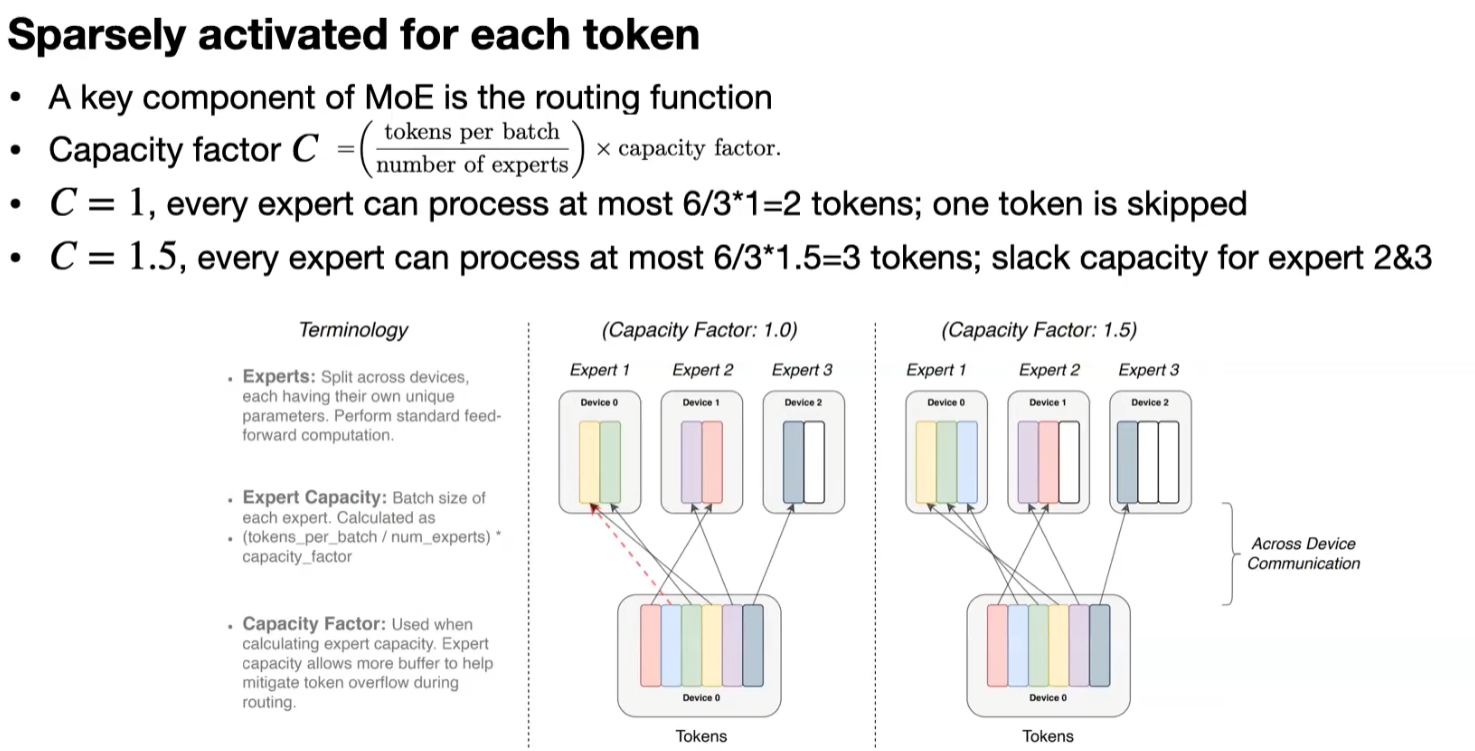
각 batch에 대해 expert들이 처리할 수 있는 token 수를 결정하는데, C=1이면 각 expert는 최대 2개의 token을 처리하고 C=1.5인 경우는 최대 3개의 token을 처리한다.

이 routing을 통해 어떤 token을 activate할지는 (1)expert를 선택하는 router를 사용하거나 (2)각 expert가 처리할 token들을 선택하거나 (3)globally 선택하는 router를 사용하는 다양한 방법이 있다.
2. Efficient inference systems for LLMs
(1) vLLM and Paged Attention
generate task에서 attention map을 계산할 때, long context에서 KV cache를 많이 저장해야함.
이러한 KV cache는 비효율성을 가지고 있는데, overflow를 막기위해서 가능한 크게 사전에 정의를 해야한다.
prompt의 출력 길이를 사전에 모르기 때문에 allocate할 수가 없다. (Internal fragmentation)
서로 다른 시퀀스 길이에 의해 메모리가 비효율적으로 사용될 수도 있다. (External fragmentation)
현재 단계에서 사용되지 않지만 미래에 사용될 슬롯이 미리 할당될 수도 있다. (Reservation)

Key-Value (KV) 캐시의 메모리 단편화 문제를 해결하는 데 초점을 맞춘 기술인 PagedAttention이 도입되었는데,
이 방법은 OS의 가상 메모리 및 paging system에서 영감을 받았다고 한다.




각 block에 4개의 token이 저장될 수 있도록 logical block을 정의하고 physical block을 block table을 이용하여 연결한다.
입력 prompt를 각 block에 token 순으로 할당을 하고, token을 생성하여 할당한다.

만약 request가 2개 이상이면 별개의 logical KV block을 이용하여 사용한다. 이렇게 되면 최대 3개의 token space의 비효율을 가져오는 이점이 있다.
KV block은 논리적으로는 시퀀스의 순서에 맞게 이어지지만, 물리적으로는 메모리 내에서 불연속적인 위치에 저장될 수 있다.

또 동일한 블록 내에서 여러 시퀀스가 공통된 값을 참조할 수 있게 해주어,즉 같은 prompt를 공유하면 동일한 block을 참조할 수 있음. 메모리 낭비를 줄이고 병렬 처리를 최적화할 수 있다.
(2) StreamingLLM
input sequence length가 길어짐에 따라 기존의 attention 기법들은 model quality가 낮아지는 문제(i.e. OOM, Performance break)가 발생한다.
OOM을 방지하기 위해서는 Window 기법을 적용하면 된다. 하지만 이러한 방식들은 아래와 같은 문제가 있다.
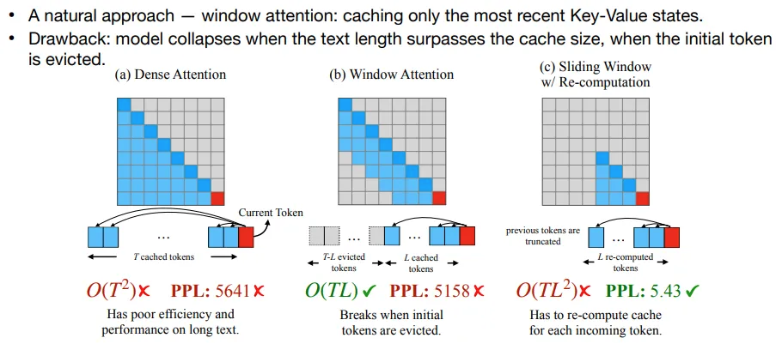
Dense Attention은 모든 token에 대해 Key-Value 상태를 유지하기에 계산 비용이 크고 long context에 대해 성능이 낮다.
Window Attention은 가장 최근에 사용된 일부 token만 cache하여 연산량은 감소할 수 있지만 cache에서 제거된 token들로 인해 성능이 저하된다.
Sliding Window with Re-computation은 이전 token이 cache에서 제거되면, 다시 계산을 통해 Key-Value를 재구성하여 연산량은 증가하지만 성능이 우수하다.
-Attention sink
-> 여기서 중요한 발견은 1st token이 semantically 중요하지 않더라도 attention score의 관점에서는 가장 중요하다는 것.
아래 예시를 보면, He가 새롭게 generate된 paper과 큰 연관성이 없지만 가장 attention score가 높은 것을 알 수 있다.
실험적으로 4개의 줄바꿈 문자를 추가한 이후에 PPL이 회복되는 것으로 보아, token의 의미보다는 위치에 더 의존한다는 결론을 얻었고, 이를 활용함.

-StreamingLLM
keep attention sinks 그리고 아래 그림의 경우 한 block에 8개의 token이 allocate된다고 한다면, rolling kv cache로 8개의 token을 받아들인다.



이 방법론은 baseline보다 22.2배 빠를 뿐만 아니라 memory효율적이라는 결론을 냈다.
(3) FlashAttention

Query와 Key의 내적을 기반으로 만들어지는 Attention Score는 메모리에 저장된 후 Softmax로 정규화되고, 그 이후에 Value와 곱셈을 진행하지만 이 과정에서 중간 계산값들이 모두 메모리에 저장되면서 메모리 낭비가 발생할 수 있습니다.
FlashAttention의 전체적인 계산 과정은 다음과 같다:
- Query와 Key의 내적을 통해 Attention Score를 계산.
- Softmax를 계산하면서 중간 Attention Score 값을 저장하지 않고 바로 적용.
- Softmax된 결과와 Value를 곱해 최종 Attention 출력.
이 과정에서 FlashAttention은 이전과 달리 Attention Score와 Softmax 값을 따로 메모리에 저장하지 않고, 계산과 Softmax를 동시에 처리
아래 github에서 발췌한 code를 살펴보면,
https://github.com/kyegomez/FlashAttention20/blob/main/attention.py#L30
attn_weights = einsum('... i d, ... j d -> ... i j', qc, kc) * scale
# [i sequence length x d dimension] query tensor(qc)와 [j sequence length x d dimension] key tensor(kc)의
# attention score를 계산함.
block_row_maxes = attn_weights.amax(dim = -1, keepdims = True)
# 각 query token에 대해 가장 최대값을 구함. -> softmax에서 overflow를 막기 위함.
new_row_maxes = torch.maximum(block_row_maxes, row_maxes)
exp_weights = torch.exp(attn_weights - new_row_maxes)
# 정규화된 Attention Score를 계산하기 위한 단계, softmax에 해당하는 값들
block_row_sums = exp_weights.sum(dim = -1, keepdims = True).clamp(min = EPSILON)
# softmax 분모
exp_values = einsum('... i j, ... j d -> ... i d', exp_weights, vc)
# 각 Query에 대한 Key와의 가중합(Value의 weighted sum)을 계산
oc.mul_(exp_row_max_diff).add_(exp_values)
#메모리 효율적으로 최종 Attention 값을 계산(4) Speculative decoding
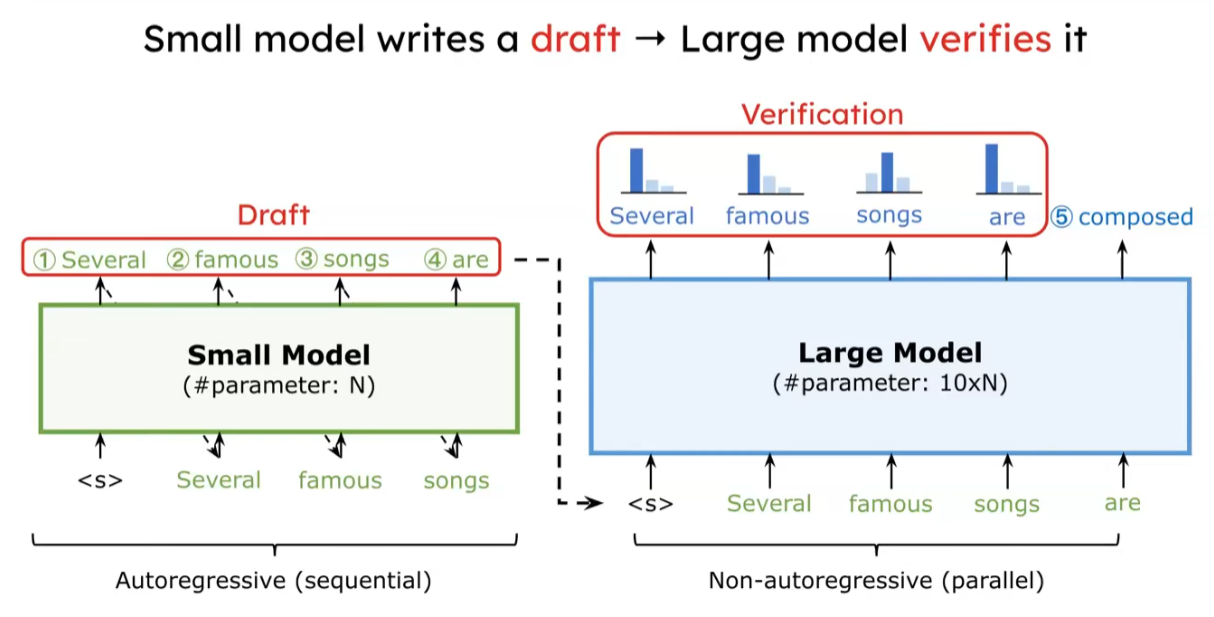
small model이 draft로 몇개의 token을 AR 방법으로 생성하면 target model이 parallel로 검증하는 것.
3. Efficient fine-tuning for LLMs
(1) LoRA/QLoRA
- LoRA

모델의 가중치 전체를 조정하는 대신 저랭크 행렬을 추가하여 가중치 변화량을 모델링하고 메모리와 계산 자원을 크게 절약하면서도 성능을 유지할 수 있어 대규모 모델을 학습할 때 유용한 방법이다.
-QLoRA

LoRA에 Quantization을 적용한 방식으로, 4bit quantization을 사용하여 더 적은 memory와 computational cost만으로도 LLM을 학습할 수 있게된다. CPU에 일부 최적화 작업을 오프로드하여 효율성을 극대화하였다.
(2) Adapter
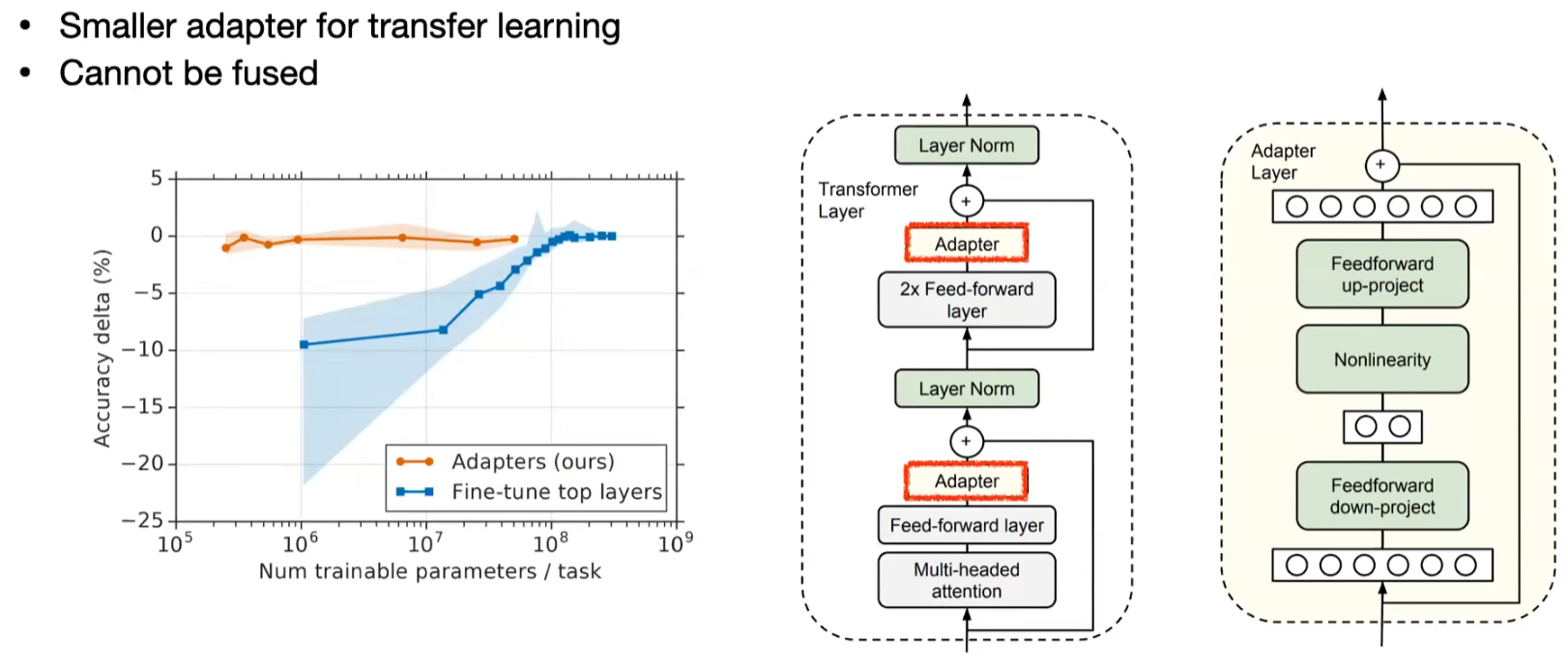
추가적인 작은 모듈을 넣어 학습하는 방식으로 Feed-forward layer와 Multi-headed Attention 사이에 삽입되어 적은 수의 parameter만을 사용하여 높은 성능을 유지할 수 있음.
(3) Prompt Tuning
특정 task마다 prompt를 학습하는 방식으로, 입력에 추가적인 프롬프트를 제공하여 모델이 주어진 작업을 더 잘 수행하도록 유도하는 방법이다. 모델이 커질수록 미세 조정과 유사한 정확도를 달성할 수 있다.
- 다른 task에 대해 학습된 여러 개의 prompt를 하나의 batch로 혼합할 수 있다. 즉, 한 번의 입력에서 여러 작업의 prompt를 처리할 수 있음.
- 학습해야 하는 파라미터 양이 적음
- 미세 조정 대비 적은 리소스를 요구함
